pandas > pivot_table 사용법
rows = mysql_util_query_to_all_dist_multithread(sql) df = pd.DataFrame(rows) df.columns = ['yyyymmdd', 'userid', 'postid', 'commentcnt'] pf = pd.pivot_table(df, index=['yyyymmdd'], values=['userid', 'commentcnt'], aggfunc={'userid':[len, pd.Series.nunique], 'comments':[np.sum, np.average]}, fill_value = 0, margins=False) print(pf) pf.to_csv("output.csv", mode='w') 이 코드를 활용하면 앞으로 시간을 많이 아낄수 있을 것 ..
더보기
판다스 > 데이터프레임 값, 메타정보 둘러보기
import pandas as pd import numpy as np import seaborn as sns import ssl from bs4 import BeautifulSoup import requests import re ssl._create_default_https_context = ssl._create_unverified_context df = pd.read_csv('/Users/pandas_sample/part3/auto-mpg.csv', header=None) df.columns = ['mpg','cylinders','displacement','horsepower','weight', 'acceleration','model year','origin','name'] # 첫 5줄 보기 print..
더보기
데이터프레임 -> 엑셀파일로 저장하기.
import pandas as pd import numpy as np import seaborn as sns import ssl from bs4 import BeautifulSoup import requests import re ssl._create_default_https_context = ssl._create_unverified_context # 판다스 DataFrame() 함수로 데이터프레임 변환. 변수 df1, df2에 저장 data1 = {'name' : [ 'Jerry', 'Riah', 'Paul'], 'algol' : [ "A", "A+", "B"], 'basic' : [ "C", "B", "B+"], 'c++' : [ "B+", "C", "C+"]} data2 = {'c0':[1,2,3],..
더보기
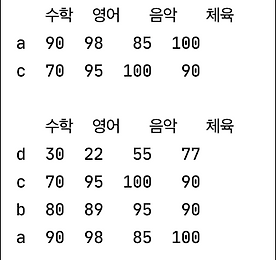 DataFrame - 범위 슬라이싱, set_index
import pandas as pd # 범위 슬라이싱 exam_data = {'수학' : [90, 80, 70, 30], '영어' : [98, 89, 95, 22], '음악' : [85, 95, 100, 55], '체육' : [100, 90, 90, 77]} df = pd.DataFrame(exam_data, index=['a', 'b', 'c', 'd']) # 2행 간격으로 슬라이싱 하려면... ret = df.iloc[::2] print(ret) # 역순으로 정렬하려면 ret = df.iloc[::-1] print(ret) 일단위, 요일단위로 순차정렬 되어있다면 슬라이싱 간격을 활용할 수 있겠다. 전체를 역순으로 정렬하는 건 알겠는데, 특정 컬럼을 선택해서 정렬하는 방법은 없을까? import pan..
더보기
DataFrame - 범위 슬라이싱, set_index
import pandas as pd # 범위 슬라이싱 exam_data = {'수학' : [90, 80, 70, 30], '영어' : [98, 89, 95, 22], '음악' : [85, 95, 100, 55], '체육' : [100, 90, 90, 77]} df = pd.DataFrame(exam_data, index=['a', 'b', 'c', 'd']) # 2행 간격으로 슬라이싱 하려면... ret = df.iloc[::2] print(ret) # 역순으로 정렬하려면 ret = df.iloc[::-1] print(ret) 일단위, 요일단위로 순차정렬 되어있다면 슬라이싱 간격을 활용할 수 있겠다. 전체를 역순으로 정렬하는 건 알겠는데, 특정 컬럼을 선택해서 정렬하는 방법은 없을까? import pan..
더보기


